最近公司在计划未来能够自己使用Hadoop环境,于是都在研究环境的搭建、和一些基本的操作。在服务器弄了三台来搭建了一个小集群环境。方便日后查阅做个记录。

环境准备:
系统版本:CentOS release 6.7 64位
软件版本:
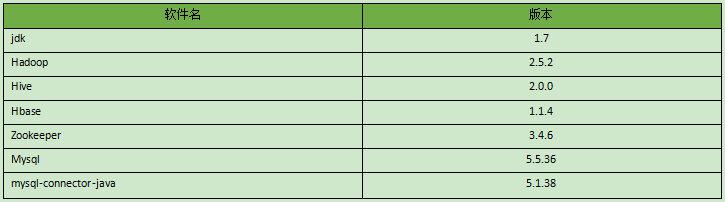
说明:Hadoop和Hive、Hbase有版本兼容的问题,原来使用的Hive-1.2.1但是在整合Hbase时出现错误一直无法解决,最后升级到Hive-2.0.0版本后,配置文件跟原来1.2.1一样,却可以实现整合。
系统规划:【此处规划不规范,SecondNameDode应该分开】

Hadoop的进程:NameNode、SecondNameDode、DataNode、JobHistoryServer
Yarn计算框架:ResourceManager、NodeManager
Hbase的进程:HMaster、HRegionServer
Zookeeper:HQuorumPeer、QuorumPeerMain
以下操作在每台机器上执行:【root用户操作】
1、关闭所有系统的防火、SELINUX配置:
service iptables stop
chkconfig iptables off
sed -i 's#enforcing#disabled#' /etc/selinux/config
2、建立hadoop【运行Hadoop 的一个普通用户,并授权sudo】
useradd hadoop
echo “123456”|passwd --stdin hadoop
SUDO 授权:
echo "hadoop ALL=(ALL) NOPASSWD: ALL" >>/etc/sudoers
3、修改主机名,IP 地址;根据上面的规划一一对应。【略】
4、修改/etc/hosts
192.168.254.18 hadoop-01
192.168.254.18 hadoop-02
192.168.254.18 hadoop-03
5、添加时间同步定时任务:
#update system time
*/15 * * * * /usr/sbin/ntpdate cn.ntp.org.cn >/dev/null 2>&1
以下操作只在Hadoop-01 主机上操作:
切换到hadoop 用户后,在家目录建立一个tools 目录用来存放软件包,建立一个app 目录把有的软件安装到此目录下:
mkdir /home/hadoop/{tools,app}
1、上传的文件有:
hadoop-2.5.2.tar.gz、apache-hive-2.0.0-bin.tar.gz、hbase-1.1.4-bin.tar.gz、jdk-7u79-linux-x64.gz、mysql-connector-java-5.1.38.tar.gz、zookeeper-3.4.6.tar.gz、mysql-5.5.36.tar.gz
2、解压所有软件到app 目录下:
cd app/
进入到app 目录中执行下面批量解压:
find /home/hadoop/tools/ -name "*.tar.gz" -exec tar zxf {} \;
6、创建软件的软连接【方便软件升级】
ln -s hadoop-2.5.2/ hadoop
ln -s apache-hive-2.0.0-bin/ hive
ln -s hbase-1.1.4/ hbase
ln -s zookeeper-3.4.6/ zookeeper
ln -s jdk1.7.0_79/ java7
7、添加环境变量:
vim ~/.bash_profile
#HDFS ENV.sh configuration
export JAVA_HOME=/home/hadoop/app/java7
export ZK_HOME=/home/hadoop/app/zookeeper
export HBASE_HOME=/home/hadoop/app/hbase
export HIVE_HOME=/home/hadoop/app/hive
export CLASS_PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export HADOOP_HOME=/home/hadoop/app/hadoop
export YARN_HOME=$HADOOP_HOME
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZK_HOME/bin:$HBASE_HOME/bin:$HIVE_HOME/bin
8、创建SSH 免密钥登陆:
ssh-keygen -q -t rsa -N "" -f /home/hadoop/.ssh/id_rsa
分到密钥到:hadoop-02,hadoop-03;同时自己也要做一个密钥认证:
ssh-copy-id -i hadoop-01
ssh-copy-id -i hadoop-02
ssh-copy-id -i hadoop-03
9、同步.bash_profile 到其它的主机上:
scp ~/.bash_profile hadoop-02:~
scp ~/.bash_profile hadoop-03:~
10、安装Mysql 服务:【Mysql 只在Hadoop-01 上运行,仅作Hive 的元数据存储,建议切换到root 用户下操作】
11、安装依懒包:
su root
yum -y install gcc gcc-c++ ncurses ncurses-devel cmake
12、添加mysql 用户
useradd -M -s /sbin/nologin mysql
13、建立存放数据的目录:
mkdir -p /data/mysql
14、编译安装:
cd mysql-5.5.36
cmake \
-DCMAKE_INSTALL_PREFIX=/usr/local/mysql-5.5.36 \
-DMYSQL_DATADIR=/data/mysql \
-DMYSQL_USER=mysql \
-DSYSCONFDIR=/etc \
-DMYSQL_TCP_PORT=3306 \
-DMYSQL_UNIX_ADDR=/tmp/mysql.sock \
-DWITH_INNOBASE_STORAGE_ENGINE=1 \
-DWITH_PARTITION_STORAGE_ENGINE=1 \
-DWITH_FEDERATED_STORAGE_ENGINE=1 \
-DWITH_BLACKHOLE_STORAGE_ENGINE=1 \
-DWITH_MYISAM_STORAGE_ENGINE=1 \
-DENABLED_LOCAL_INFILE=1 \
-DENABLE_DTRACE=0 \
-DDEFAULT_CHARSET=utf8mb4 \
-DDEFAULT_COLLATION=utf8mb4_general_ci \
-DWITH_EMBEDDED_SERVER=1
编译安装
make -j `grep processor /proc/cpuinfo | wc -l`
#编译很消耗系统资源,小内存可能编译通不过
make install
15、添加到开机启动服务:
/bin/cp /usr/local/mysql-5.5.36/support-files/mysql.server /etc/init.d/mysqld
chmod +x /etc/init.d/mysqld
chkconfig --add mysqld
chkconfig mysqld on
16、/etc/my.cnf,仅供参考 【详情参考文章后的PDF文档】
17、初始化数据库,并启动服务:
/usr/local/mysql/scripts/mysql_install_db --user=mysql --group=mysql --basedir=/usr/local/mysql --datadir=/data/mysql
service mysqld start
18、登陆Mysql 并创建一个名为hive 的用户,和数据库,并授权登陆。
create database hive;
grant all privileges on hive.* to “hive”@”%” indentified by “123456”;
flush privileges;
Hadoop 的配置:
进入配置文件目录:cd /home/hadoop/app/hadoop/etc/hadoop/
1、修改配置文件:core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hadoop/tmp</value>
</property>
<property>
<name>heartbeat.recheck.interval</name>
<value>1000</value>
</property>
</configuration>
`
2、修改配置文件:hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-01:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/app/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/app/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
3、修改配置文件:yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop-01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop-01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop-01:8031</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
</configuration>
4、修改配置文件:mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>
</configuration>
5、修改配置文件:hadoop-env.sh 加入JAVA 安装目录:
export JAVA_HOME=/home/hadoop/app/java7
6、修改配置文件: master 【由于SecondNameDode 也在同一主机上,所以写上,如果环境允许不建议此配置。】
echo “hadoop-01” >master
7、修改配置文件: slaves 【写上所有DataNode 节点】
hadoop-02
hadoop-03
Hive 的配置:
进入配置文件目录:cd /home/hadoop/app/hive/conf
1、修改配置文件: hive-site.xml
cp hive-default.xml.template hive-site.xml
<property>
<name>hive.exec.local.scratchdir</name>
<value>/home/hadoop/app/hadoop/tmp</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/home/hadoop/app/hadoop/tmp</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.254.18:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
2、修改配置文件:hive-env.sh
cp hive-env.sh.template hive-env.sh
HADOOP_HOME=/home/hadoop/app/hadoop
export HIVE_CONF_DIR=/home/hadoop/app/hive/conf
3、修改配置文件:
cp hive-log4j2.properties.template hive-log4j2.properties
4、把mysql-connector-java-5.1.38-bin.jar 复制到hive/lib/目录下:
cp tools/mysql-connector-java-5.1.38/mysql-connector-java-5.1.38-bin.jar /home/hadoop/app/hive/lib/
5、初始化Hive 元数据【元数据会根据上面的配置文件写入到Mysql 中的Hive 库】
cd /home/hadoop/app/hive/bin
./schematool -dbType mysql -initSchema
说明:在hive-1.1.4 的版前都要先启动hive —service metastore & 和hive —service hiveserver2 &服务才可以登陆到hive 命令行,但
是在2.0.0 版本发现不用启动也可以直接登陆命令。
Hive 上创建的表数据可以直接在Mysql 中查询到,表的一些记录信息:
select * from hive.TBLS;
HBASE 的配置:
cd /home/hadoop/app/hbase/conf
1、修改配置文件:hbase-env.sh
export JAVA_HOME=/usr/local/java7
export HBASE_CLASSPATH=/home/hadoop/app/hbase/conf
export HBASE_LOG_DIR=${HBASE_HOME}/logs
export HBASE_PID_DIR=/home/hadoop/app/hbase/tmp
2、修改配置文件:hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop-01:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.master</name>
<value>192.168.254.18</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>192.168.254.19,192.168.254.28</value>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
</configuration>
3、修改配置文件:regionservers 【Hbase 各个节点的主机名或IP 地址】
192.168.254.18
192.168.254.19
192.168.254.28
由于Hbase 需要Zookeeper 来调度,这里我们使用自己安装的,不用自带的如果需要启动自带的zookeeper 即需要
在hbase-env.sh 文件中启动:export HBASE_MANAGES_ZK=true
Zookeeper 的配置:
cd /home/hadoop/app/zookeeper/conf
1、修改配置文件:zoo.cfg
cp zoo_sample.cfg zoo.cfg
[hadoop@hadoop-01 conf]$ egrep -v "^#|^$" zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/hadoop/app/zookeeper/data
dataLogDir=/home/hadoop/app/zookeeper/logs
clientPort=2181
server.1=192.168.254.18:2888:3888
server.2=192.168.254.19:2888:3888
server.3=192.168.254.28:2888:3888
2、添加每个主机的Myid:【根据配置文件zoo.cfg 的server.X 对应】
echo 1 >/home/hadoop/app/zookeeper/data/myid
基本上配置完成,接下来把上面整个app 目录同步到其它节点:hadoop-02、hadoop-03 上:
scp -r app/ hadoop-02:~
scp -r app/ hadoop-03:~
由于上面已经同步了~/.bash_profile 文件,此时在各节点的环境变量已经正常了,可以直接执行相关的命令了:
注意:由于上面的zookeeper 的myid 是要一一对应的。
在hadoop-02 上执行:
echo 2 >/home/hadoop/app/zookeeper/data/myid
在hadoop-03 上执行:
echo 3 >/home/hadoop/app/zookeeper/data/myid
一切准备好后,格式化NameNode:【在Hadoop-01 节点上操作】
hadoop fs -format namenode
启动服务:
1、启动HDFS:
cd /home/hadoop/app/hadoop/sbin/
./start-dfs.sh
2、启动Yarn 计算框架:
./start-yarn.sh
3、启动Jobhistory 服务:
./mr-jobhistory-daemon.sh start historyserver
4、启动zookeeper 服务:每台服务器上分别启动:最好按【zoo.cfg】配置文件中顺序的启动:
/home/hadoop/app/zookeeper/bin/zkServer.sh start
5、启动Hbase 服务:【只需要在Hadoop-01 节点上操作】
/home/hadoop/app/hbase/bin/start-hbase.sh
./start-dfs.sh
6、检查服务是否正常运行:
jps
更详细可参考PDF文档:Hadoop+Hbase+Hive+Zookeeper集群.pdf
链接: https://pan.baidu.com/s/1KvyMJ7fXKFgcP6J3oMfcgg 密码: 6ite