Hadoop伪分布模式:在单节点上同时启动NameNode、DataNode、JobTracker、TaskTracker、Secondary Namenode等5个进程,模拟分布式运行的各个节点;
1、Hadoop搭建环境:
虚拟机操作系统: CentOS6.5 64位,单核,1G内存
JDK:1.7.0_79 64位
Hadoop:2.5.2
2、本地环境:
IP:10.0.10.50
2.1 设置机器名
vi /etc/sysconfig/network打开配置文件,根据实际情况设置该服务器的机器名,新机器名在重启后生效
[root@hadoop01 ~]# hostname
hadoop01
2.2 设置Host文件,IP地址与机器名的映射,设置信息如下:
[root@hadoop01 ~]# vim /etc/hosts
10.0.10.50 hadoop01
2.3 建立hadoop用户(其实用户名你随意)
[root@hadoop01 ~]# useradd hadoop
[root@hadoop01 ~]# echo "hadoop" |passwd --stdin hadoop
更改用户 hadoop 的密码 。
passwd: 所有的身份验证令牌已经成功更新。
2.4 切换到上面hadoop用户,并配置ssh-key:
[root@hadoop01 ~]# su hadoop
[hadoop@hadoop01 root]$ cd
[hadoop@hadoop01 ~]$ ssh-keygen -t dsa
Generating public/private dsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_dsa):
Created directory '/home/hadoop/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_dsa.
Your public key has been saved in /home/hadoop/.ssh/id_dsa.pub.
The key fingerprint is:
b8:5a:8b:7f:74:05:50:68:f3:d5:d9:e7:7f:bb:aa:25 hadoop@hadoop01
The key's randomart image is:
+--[ DSA 1024]----+
| .+. . o |
| + . . o o|
| . o o ..|
| . . . .|
| . S . .|
| .. . o|
| o. . E . o|
| + .. o . |
| o.o. ......|
+-----------------+
2.5 复制一份KEY给自己,实现自己免密钥登陆:
[hadoop@hadoop01 ~]$ ssh-copy-id -i .ssh/id_dsa.pub hadoop@hadoop01
The authenticity of host 'hadoop01 (10.0.10.50)' can't be established.
RSA key fingerprint is 3f:8d:5d:d4:5d:1d:08:88:02:f1:1e:05:41:60:84:10.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'hadoop01,10.0.10.50' (RSA) to the list of known hosts.
hadoop@hadoop01's password:
Now try logging into the machine, with "ssh 'hadoop@hadoop01'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
以下修改要在root权限下操作:
3、首先,挂载系统光盘,安装lrzsz-0.12.20-27.1.el6.x86_64.rpm 包,此工具是上传下载的软件。
[root@hadoop01 ~]# mount /dev/cdrom /mnt
[root@hadoop01 ~]# rpm -ivh /mnt/Packages/lrzsz-0.12.20-27.1.el6.x86_64.rpm
4、把所需要的软件上传到/root/tools目录:
[root@hadoop01 tools]# ls
hadoop-2.5.2.tar.gz jdk-7u79-linux-x64.rpm
5、安装JDK环境
[root@hadoop01 tools]# rpm -ivh jdk-7u79-linux-x64.rpm
安装完成后无法运行jps命令的,可以直接作一个符号链接即可。
[root@hadoop01 tools]# ln -s /usr/java/jdk1.7.0_79/bin/jps /usr/bin/jps
6、安装hadoop-2.5.2,我这里把hadoop-2.5.2安装到/app目录下(其实解压到指定目录即完成安装),目录自己随意。
[root@hadoop01 tools]# mkdir /app
[root@hadoop01 tools]# ls
hadoop-2.5.2.tar.gz jdk-7u79-linux-x64.rpm
[root@hadoop01 tools]# tar xf hadoop-2.5.2.tar.gz -C /app
[root@hadoop01 tools]# cd /app/hadoop-2.5.2/
[root@hadoop01 hadoop-2.5.2]# ls
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share
7、配置hadoop环境,由于我这里是单机实现伪分布式安装,所以所有的都安装在一台服务器。
7.1 在hadoop-2.5.2目录下创建子目录,并授权目录:
cd /app/hadoop-2.5.2
mkdir tmp
mkdir hdfs/{name,data} -p
授权:(如果不授权无法写入日志,临时文件等)
chown -R hadoop.hadoop /app/hadoop-2.5.2/
进入此目录修改以下配置文件:
[root@hadoop01 hadoop]# pwd
/app/hadoop-2.5.2/etc/hadoop
7.2 编译配置文件hadoop-env.sh并确认生效
[root@hadoop01 hadoop]# vim hadoop-env.sh
第26行左右:修改JDK路径
26 export JAVA_HOME=/usr/java/jdk1.7.0_79
使之生效:
[hadoop@hadoop01 hadoop]$ source hadoop-env.sh
7.3 配置core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<!-- 此处是机器名:hadoop:90000 端口. -->
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<!-- 此处是hadoop的临时目录,上面手工建立的。 -->
<value>/app/hadoop-2.5.2/tmp</value>
</property>
</configuration>
7.4 配置hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/app/hadoop-2.5.2/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/app/hadoop-2.5.2/hdfs/data</value>
</property>
</configuration>
7.5 配置mapred-site.xml
要修改名字:
[root@hadoop01 hadoop]# mv mapred-site.xml.template mapred-site.xml
[root@hadoop01 hadoop]#vim mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop01:9001</value>
</property>
</configuration>
7.6 环境变量问题:
添加一个符号链接:解决(Error: Cannot find configuration directory: /etc/hadoop)问题
ln -s /app/hadoop-2.5.2/etc/hadoop/ /etc/hadoop
或者添加最后两行在以下配置中:
cat >>/etc/profile<<-EOF
export JAVA_HOME=/usr/java/jdk1.7.0_79
export HADOOP_HOME=/app/hadoop-2.5.2
export PATH=$PATH:$HADOOP_HOME/bin:$JAVA_HOME/bin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YANR_CONF_DIR=$HADOOP_HOME/etc/hadoop
EOF
执行使之生效:
source /etc/profile
以下在hadoop用户下操作:
7.7 格式化namenode (切换到 hadoop用户执行)
hadoop namenode -format
7.8 启动hadoop (切换到 hadoop用户执行)
cd /app/hadoop-2.5.2/sbin
[hadoop@hadoop01 sbin]$ ./start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
16/01/09 16:07:23 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [hadoop01]
hadoop01: starting namenode, logging to /app/hadoop-2.5.2/logs/hadoop-hadoop-namenode-hadoop01.out
localhost: starting datanode, logging to /app/hadoop-2.5.2/logs/hadoop-hadoop-datanode-hadoop01.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /app/hadoop-2.5.2/logs/hadoop-hadoop-secondarynamenode-hadoop01.out
16/01/09 16:07:41 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
starting yarn daemons
starting resourcemanager, logging to /app/hadoop-2.5.2/logs/yarn-hadoop-resourcemanager-hadoop01.out
localhost: starting nodemanager, logging to /app/hadoop-2.5.2/logs/yarn-hadoop-nodemanager-hadoop01.out
7.9 用jps命令查看hadoop相关进程是否启动:(切换到 hadoop用户执行)
[hadoop@hadoop01 sbin]$ jps
28238 NameNode
28508 SecondaryNameNode
28741 NodeManager
28328 DataNode
28648 ResourceManager
29036 Jps
如果有上面5个服务在运行说明hadoop成功启动。
8、打开浏览器检查效果:(看到如下效果说明成功配置)
http://10.0.10.50:50070/ Namenode information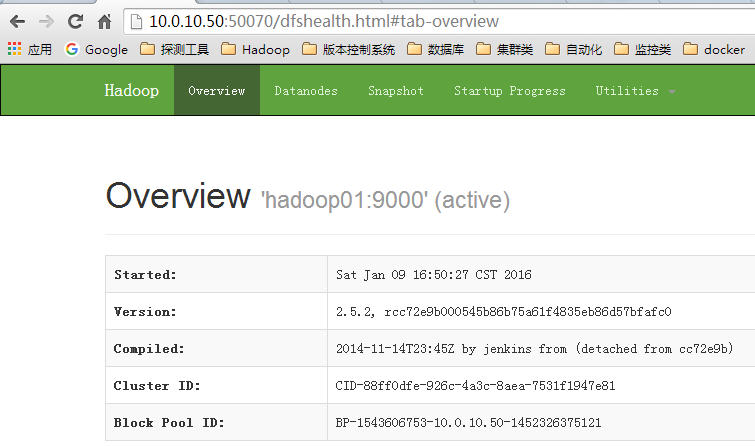
http://10.0.10.50:8088/ hadoop cluster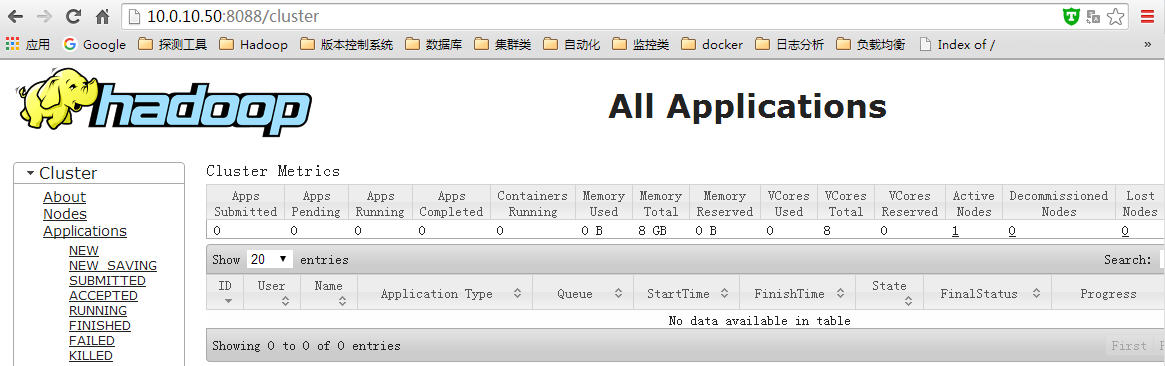
http://10.0.10.50:50090/ SecondaryNamenode information
注意:
启动服务时出现警告:
16/01/09 16:07:23 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
原因:系统中的glibc的版本和libhadoop.so需要的版本不一致导致。
检查是否不一致:(hadoop中使用的glibc版本为GLIBC_2.14)
[hadoop@hadoop01 sbin]$ ldd /app/hadoop-2.5.2/lib/native/libhadoop.so.1.0.0
/app/hadoop-2.5.2/lib/native/libhadoop.so.1.0.0: /lib64/libc.so.6: version `GLIBC_2.14' not found (required by /app/hadoop-2.5.2/lib/native/libhadoop.so.1.0.0)
linux-vdso.so.1 => (0x00007fff071ff000)
libdl.so.2 => /lib64/libdl.so.2 (0x00007f6550669000)
libc.so.6 => /lib64/libc.so.6 (0x00007f65502d4000)
/lib64/ld-linux-x86-64.so.2 (0x00000036a7000000)
而系统中的版本:(指向为2.12)
[hadoop@hadoop01 sbin]$ ll /lib64/libc.so.6
lrwxrwxrwx. 1 root root 12 12月 25 11:30 /lib64/libc.so.6 -> libc-2.12.so
解决方法有两种:
方法一:自己手工编译hadoop源码包,因此是自己的环境,那肯定是兼容的。
方法二:源码升级glibc版本。