记得很早以前用过火车头网页抓取工具,当时觉得非常牛B,这个工具可以说是推动了国内互联网的快速发展。只有经历过的才知道;当然那也是大叔级的人了,现在都流行使用Python开发爬虫。目前可以说很多公司处理数据都会用到。所以也顺着方向学了一下爬虫,本来是看到爬妹子图的教学,但是那网站做了些反爬机制,目前功夫浅啊;只能用自己的博客研究一下。
本次使用环境:
Ubuntu:16.04
Python:3.5.2
要用到的两个基本库,requests和BeautifulSoup4;还有就是chrome的开发者工具,通过它可以快速让我们找到网页的标签。
简单的爬虫框架,此图是参考天善学院的教程时自己动手画的。

本次是很简单的只爬取封尘网站内所有文章的URL地址,下一次再把所有的文章保存入库。
直接上代码:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Time : 2017/8/2 9:19
# @Author : Swper
# @Site : http://www.58jb.com/
# @Contact :hz328@qq.com
# @File : t1.py
# @Software: PyCharm
import requests
from bs4 import BeautifulSoup
#获取列表页所有链接:
def listLinks(url):
urlList = []
res = requests.get(url)
soup = BeautifulSoup(res.text,'html.parser')
for link in soup.select('.excerpt li'):
a = link.select('a')[0]['href']
full_url = 'https://www.58jb.com' +a #因为默认网站只有相对地址,所以要补全
print(full_url)
#利用range产生多个分页;
url = 'https://www.58jb.com/page/{}.html'
url_total = []
for i in range(1,7):
newsurl = url.format(i)
newsary = listLinks(newsurl)
#最后调用函数时就可以获取到所有的网页URL地址了。
listLinks(url)
不到三十行的代码,真过隐啊。最后效果就出来了:
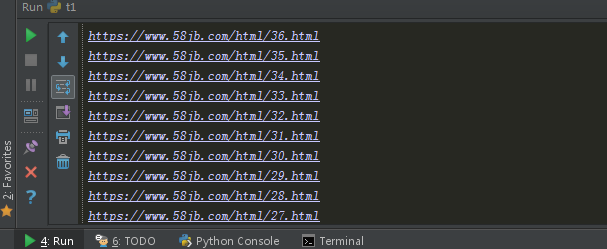
由于自己的网站设计简单,很容易就做出来,新手先拿自己的练习练习。
当看到所有的URL地址时才发现,博客自从改版以来原来更新的量是这么少啊。