Hadoop集群由6个节点。24核心、64G的小群集;上线已经运行了近200天了;一直还算稳定,但问题就在于前几天集群中断断续续的报了一个异常信息;
Hadoop集群-Hd2 os process 警告 too more process running
由于是警告,但是我也登陆系统查看了进程和线程都没有达到限制的数量,内存、CPU、硬盘等都感觉正常的,于是就没有理会;但是昨天下午终于爆发了,NameNode上的所有服务进程全部退出了,ssh连上系统后查看系统日志,没什么异常;由于能正常登陆系统,日志没发现异常所以直接尝试把服务启动;输入命令都报错了;
切到root用户也一样;不可能被入侵啊,集群在内部运行;
bash: /usr/bin/reboot: Input/output error
[root@hd1 bin]# whoami
Segmentation fault
[root@hd1 ~]# reboot
bash: /usr/bin/reboot: Input/output error
[root@hd1 ~]# init 6
Bus error
[root@hd1 ~]# touch 12
touch: cannot touch `12': Read-only file system
You do not have enough privileges to perform this operation.
根据上面几个命令下来,初步确定是盘问题了;立刻到机房查看,两块硬盘一块闪黄灯了,闪得很频呢;接上显示器后,内核已经报错了系统崩了。 断电重启,发现rdid上面只有一块盘,由于是raid损坏一块就没了。至于为什么不做raid5呢,当时考虑也只是先测试用着,后来硬着用了。这下问题出来了,只能把NameNode切到另一个节点上;由于没试过Secondary Namenode的切换,所以直接在另一节点上变更为NameNode;至于HDFS上的数据,由于写入的数据在本地也存有数据,而且旧的数据暂时可以不用。最后启动5个节点了,工作正常;
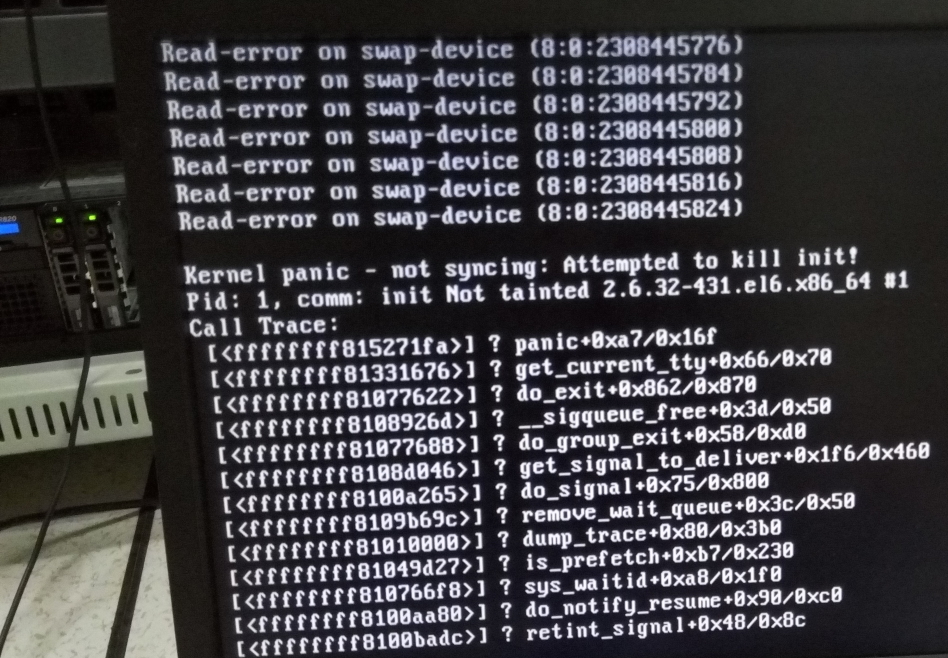
问题分析:
1、系统在配置的时候由于没考虑全面,根据拍到图片来说硬件上没做的数据的备份;【raid没做到位,至少在5或者50】
2、系统不管内存多大,至少都在划分一部分swap分区;因为上面的系统没划分swap分区;而系统内存跑满后,又没有swap分区写入,导致不断的报异常;too more process running我猜就是写swap报的;
3、之前有于Hive写的日志特别大这是一个问题,也有可能是导致磁盘IO问题;建议在hive-log4j2.properties 修改status = ERROR ,或者把property.hive.log.dir = /data/hive_logs 日志打到另一个磁盘上;
4、要不断的测试做实验,比如Secondary Namenode的切换;只有在不断的测试演练才能更准确的发现问题和解决问题;
虽然这次的问题影响不大,但对于我来说也是一个严重的问题;仅此记录,也希望各位不要遇到我这样的情况;