Tez是从MapReduce计算框架演化而来的通用DAG计算框架,可作为MapReduceR/Pig/Hive等系统的底层数据处理引擎,它天生融入Hadoop 2.0中的资源管理平台YARN。
Tez有以下几个特色:
- 丰富的数据流接口;
- 扩展性良好的“Input-Processor-Output”运行模型;
- 简化数据部署(充分利用了YARN框架,Tez本身仅是一个客户端编程库,无需事先部署相关服务)
- 性能优于MapReduce
- 优化的资源管理(直接运行在资源管理系统YARN之上)
- 动态生成物理数据流
hive on tez,直接配置hive支持tez,其实是在yarn上面启动一个app,这个app永久运行,接受不同sql,除非退出hive cli此app才会结束
tez runing app在yarn上面和spark on yarn很类似,而且tez,spark底层原理也很相似!
在切换底层为mr引擎的时候也会重启app运行,但是tez那个app也没结束,等待mr app运行结束后,两个一起结束!
原本打算自己编译的,发现编译到tez-ui的时候总是报错,除非跳过不使用tez-ui;多次编译都是失败了,暂时先放一边了;直接使用官网已经编译好的包吧;
备注:Tez-ui是一个 Web界面可以看到Job的信息的执行时间,通过它可以更好、更直观的了解到程序慢在哪个位置;
集群测试环境:
192.168.18.56 spark.hd1 [NameNode]
192.168.18.57 spark.hd2 [DataNode]
192.168.18.58 spark.hd3 [DataNode]
在NameNode节点上操作:
官网下载Tez包:
https://mirrors.tuna.tsinghua.edu.cn/apache/tez/0.8.4/apache-tez-0.8.4-bin.tar.gz
解压:
tar xf apache-tez-0.8.4-bin.tar.gz
cd apache-tez-0.8.4-bin
由于要把tez.tar.gz包上传到HDFS上面,所以在HDFS创建一个目录:
[otouser@spark apache-tez-0.8.4-bin]$ hdfs dfs -mkdir /app
上传文件到/app目录下:
[otouser@spark apache-tez-0.8.4-bin]$ hdfs dfs -put share/tez.tar.gz /app
检查是否上传成功:
[otouser@spark apache-tez-0.8.4-bin]$ hdfs dfs -ls /app
Found 1 items
-rw-r--r-- 2 otouser supergroup 42892768 2016-12-23 13:52 /app/tez.tar.gz
添加tez-site.xml修改配置文件,让tez支持Hive:
cd hadoop/etc/hadoop/ Hadoop的配置目录下;cat tez-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/app/tez.tar.gz</value>
</property>
<property>
<name>tez.history.logging.service.class</name>
<value>org.apache.tez.dag.history.logging.ats.ATSHistoryLoggingService</value>
</property>
<property>
<description>URL for where the Tez UI is hosted</description>
<name>tez.tez-ui.history-url.base</name>
<value>http://spark.hd1:9999/tez-ui/</value>
</property>
<property>
<name>tez.runtime.convert.user-payload.to.history-text</name>
<value>true</value>
</property>
<property>
<name>tez.task.generate.counters.per.io</name>
<value>true</value>
</property>
</configuration>
yarn-site.xml 添加以下几行配置:用于tez-ui获取tez引擎的数据;
<configuration>
<property>
<name>yarn.timeline-service.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.timeline-service.hostname</name>
<value>spark.hd1</value>
</property>
<property>
<name>yarn.timeline-service.http-cross-origin.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.timeline-service.generic-application-history.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.system-metrics-publisher.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.timeline-service.address</name>
<value>${yarn.timeline-service.hostname}:10200</value>
</property>
<property>
<name>yarn.timeline-service.webapp.address</name>
<value>${yarn.timeline-service.hostname}:8188</value>
</property>
<property>
<name>yarn.timeline-service.webapp.https.address</name>
<value>${yarn.timeline-service.hostname}:8190</value>
</property>
<property>
<description>Handler thread count to serve the client RPC requests.</description>
<name>yarn.timeline-service.handler-thread-count</name>
<value>10</value>
</property>
<property>
<name>yarn.timeline-service.generic-application-history.enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.timeline-service.generic-application-history.store-class</name>
<value>org.apache.hadoop.yarn.server.applicationhistoryservice.FileSystemApplicationHistoryStore</value>
</property>
</configuration>
把上面的配置修改完后同步到每个节点上;
for h in spark.hd2 spark.hd3 ; do rsync -vaz --exclude=logs /home/otouser/software/hadoop/etc/ $h:~/home/otouser/software/hadoop/etc/ ; done
由于我的Hive也是安装在NameNode节点上,所以:
修改hive-env.sh配置:加入以下几行配置:
export HADOOP_USER_CLASSPATH_FIRST=true
export TEZ_HOME=/home/otouser/software/apache-tez-0.8.4-bin
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$TEZ_HOME/*:$TEZ_HOME/lib/*
由于tez-ui是基于Tomcat下运行的一个项目,所以我也在Hive的节点上部署了一个Tomcat程序;
把Tomcat目录下的webapps里的文件删除,再把把上面的apache-tez-0.8.4-bin 下的tez-ui2-0.8.4.war 复制到webapps目录里:
cp apache-tez-0.8.4-bin/tez-ui2-0.8.4.war /home/software/tomcat7/webapps/tez-ui.war
这里的名字注意跟上面tez-site.xml配置文件里的要相同:
修改Tomcat的配置文件:service.xml 修改8080端口为9999,也是跟上面的配置一样;
通过上面可以看出:
修改过的tez-site.xml和yarn-site.xml要同步到Hadoop各个节点上。
但是tez在这里只安装在Hive节点上,同时也部署了一个Tomcat服务;
启动方法:
由于上面修改过了配置,所以要重新启动HDFS集群和Hive程序;而且还要启动一个叫:timelineserver服务;
./stop-all.sh #停止HDFS集群
./start-dfs.sh
./start-yarn.sh
./mr-jobhistory-daemon.sh start historyserver
./yarn-daemon.sh start timelineserver #必须要先启动HDFS集群后才可以启动起来
[otouser@spark sbin]$ jps
23642 NameNode
24515 ApplicationHistoryServer #这个就是timelineserver服务
24835 Jps
24391 JobHistoryServer
24800 Bootstrap #这个就是Tomcat启动的项目:tez-ui
23891 SecondaryNameNode
24071 ResourceManager
启动Hive:
nohup hive --service metastore &
nohup hive --service hiveserver2 &
进入Hive命令操作窗口;切换到tez引擎;
hive> use test;
hive> set hive.execution.engine=tez;
hive> select count(*) from product;
Query ID = otouser_20161223150809_afbcd62c-76eb-4126-84c9-915ff6fa94ea
Total jobs = 1
Launching Job 1 out of 1
Status: Running (Executing on YARN cluster with App id application_1482476260992_0001)
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
Map 1 .......... container SUCCEEDED 4 4 0 0 0 0
Reducer 2 ...... container SUCCEEDED 1 1 0 0 0 0
----------------------------------------------------------------------------------------------
VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 27.28 s
----------------------------------------------------------------------------------------------
OK
1548417
Time taken: 30.694 seconds, Fetched: 1 row(s)
以下图是昨天截取的;
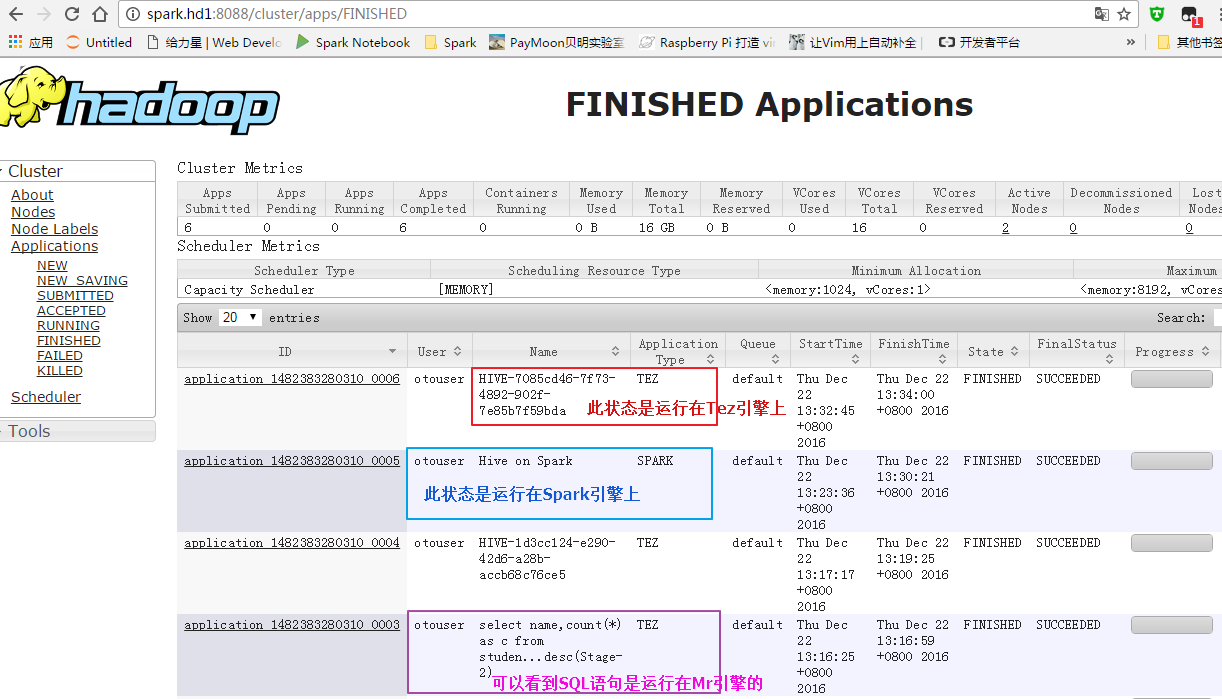
此时再查看Tez-ui界面:
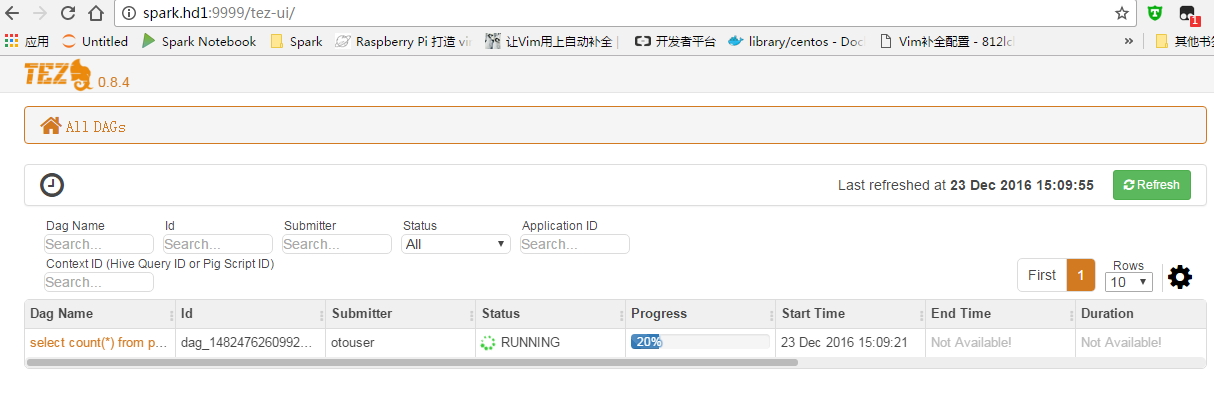
总结:我的环境中使用Hadoop-2.7.2,直接使用官网的包是没问题的,但是由于之前编译Tez包时总报错,浪费了很多时间,而且Tez目前的社区还不是很活沃,所以遇到很多问题。这里主要是做一个测试对比现有Mr的速度,效率;在简单的测试发现Tez确实是比Mr有提升,但稳定性还有待一段时间的测试使用;Spark在计算里是快,但是在我简单的测试sql语句时,并不比Tez快;